Server-side tagging:
What it means for publishers
Server Side Tagging is now part of the Google Tag Manager platform. When this was introduced in 2020, this caused quite the buzz among tech crowds due to its potential to transform the way businesses collect and use data.
But as a publisher:
- Why should you care about server-side tagging?
- What impact will it have on your digital publishing platform?
- And how can you harness this change in a practical way to drive better business results?
To answer these questions, we’ve enlisted the help of Jacob Moran, Digital analytics guru and consultant at specialist data and analytics consultancy, Lee Jane Digital. Jacob is a regular commentator on all things data and has previously worked as Sitecore practitioner, scrum master and head of delivery at Melbourne-based tech agency Hammajack.
But before we dive into the details, here’s a quick Google Tag Manager (GTM) crash course, courtesy of Jacob, for those with a non-technical background.
What is Google Tag Manager?
Google Tag Manager, as the name suggests, allows you to manage tags on your website. The most common types of tags you’d be running through GTM include analytics trackers, like Google Analytics, Facebook Pixel and so on. It’s been game-changer for marketing and product managers. GTM provides greater control over the tags they run on a website without having to frequently engage programmers to make trivial updates.
READ MORE: Ten events publishers can easily start tracking in Google Tag Manager
How did tracking work before server-side tagging?
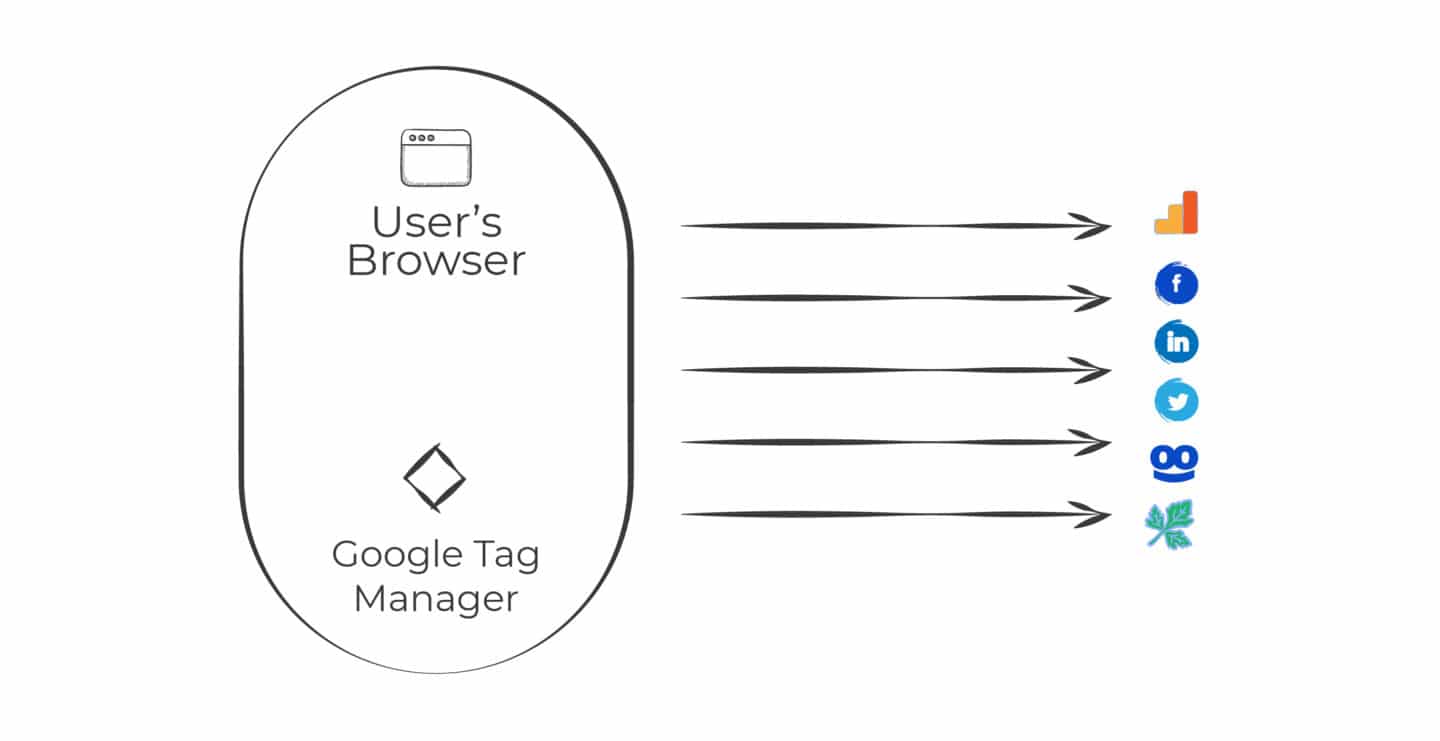
GTM has been around for almost eight years and has always operated through the browser. For example, as a publisher, if you wanted to send information to Facebook or Google Analytics, it would be loaded in the browser through a Google-hosted server. This is known as client-side tagging. Your device’s browser (the client) would download GTM in the background, which then loads the individual trackers or analytics scripts.
What are the disadvantages of client-side tagging?
Page Load
What you can do with GTM is effectively infinite, so it can become very taxing on a user’s device. For example, you might load ‘Script A’ but then ‘Script A’ loads six other scripts. If you’re using a mobile device over 4G, this is likely to cause issues from a page load perspective.
There are ways around this; a lot of publishers use AMP to load what are essentially ‘light’ versions of the page. But it doesn’t solve the issue of how to download large volumes of information without damaging your UX.
A common misconception is that moving tracking code from the website directly to a GTM container will speed up the site. This is essentially moving the problem; the underlying code is still running and still impacting performance.
Data security
With client-side tagging, when a user loads Facebook (or whatever program they might be using) onto the page, it has access to everything inside the browser. This includes the user agent stream and the user IP – which tells Facebook the location of that user plus anything else that the browser is able to access on the device.
For example, if a user opens up a web page, types in their email address and hits reload; some websites might put that email address in the query stream or save it as cookies. This means Google Analytics now has access to that information and is the reason why email addresses turn up in analytics. This is against Google’s terms and conditions and shouldn’t happen – but it does, all the time. Google Analytics is simply pulling everything it can get its hands on. It’s merciless!
Google Developer Expert, Simo Ahava explains this well in his server-side tagging article:
“There are no data leaks with third-party cookies, there are no surprises with injected URL parameters, and the third-party service doesn’t have any connection with the user’s browser by default. They’ll be communicating just with the cloud machine.”
Simo Ahava
How does server-side tagging work?
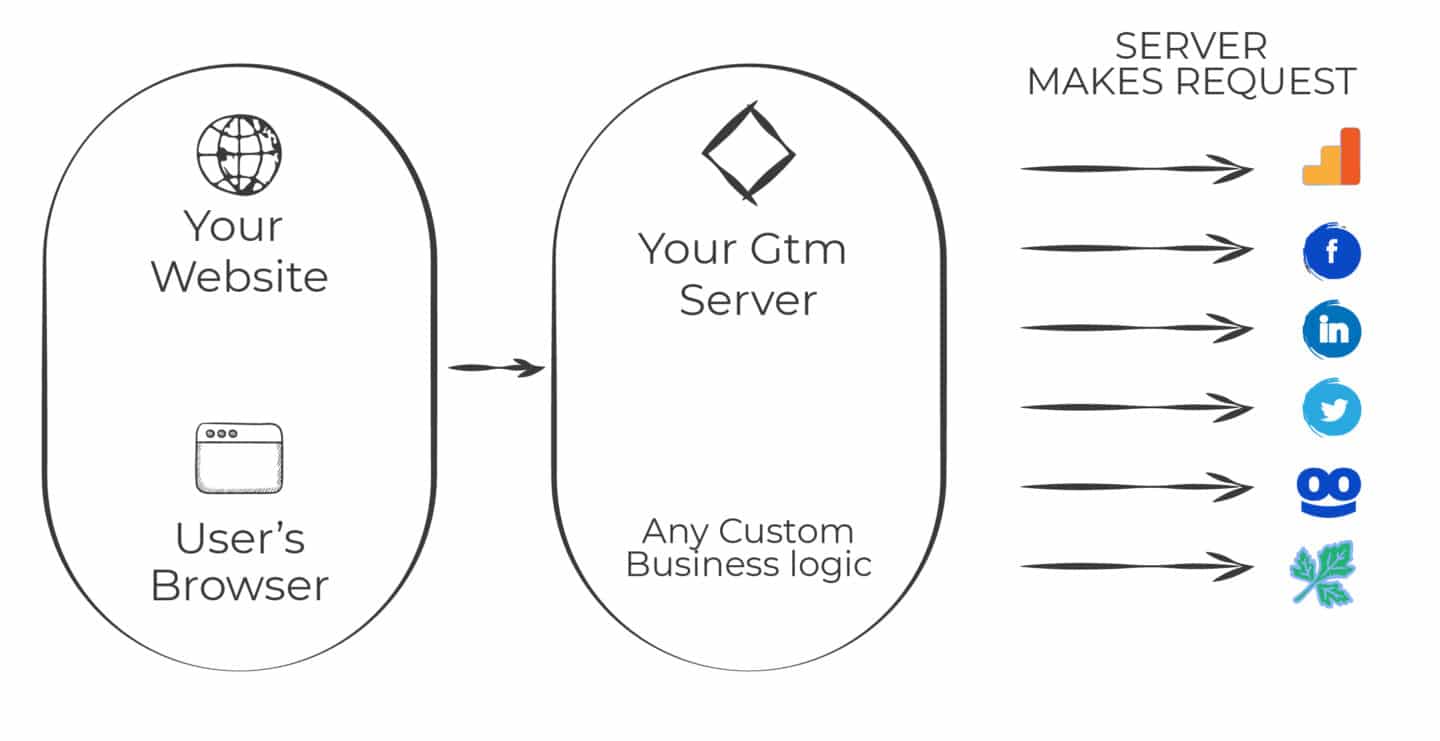
Server-side tracking works by creating a custom endpoint for the analytics calls that your website makes. This endpoint is on a server that you control and have provisioned (e.g. analytics.yourdomain.com)
With client-side tracking the analytics hits (events, transactions, pageviews, etc.) that your regular GTM container are usually sent straight to your analytics tools (i.e. Google Analytics and Facebook). In server-side tracking these hits are first sent to your server, which then figures out what to do with that data.
So instead of having multiple streams of data going to multiple places, you have one stream coming to and from your website.
And it’s from this stream (rather than from your device) that you decide how you’re going to use the information.
How does server-side tagging impact digital publishers?
Online media websites are some of the worst offenders when it comes to having excessive trackers. Due to their rich media content, pages are typically really big. Not to mention how many different places they’re sending information to. I recently read an article where the author looked at 80 different newspapers and measured how many requests were made during the time it took to read the publication. Here’s what he discovered:

“If we want to fix ad tech and privacy, 2020 is the year to do it” Thomas Baekdal – Aug 2020
According to this study, The Daily Mail made a staggering 3,233 network requests. The Guardian made 517 requests, and the Washington Post made 367. Looking at this, it’s easy to see why having a single stream of data is a game-changer for the media industry.
A single stream of data will also reduce the likelihood of data leaks and breaches, which are a growing concern for almost every industry. In fact, user privacy issues have become so widespread, Apple recently centred its entire advertising campaign around this issue.
7 Benefits of server-side tagging for publishers
1. Reduce your page sizes by up to 30%.
Moving the trackers server-side eliminates the need for your browser to load clunky javascript files. Google has long said that having GTM, Google Analytics and other Google products on the site does not affect SEO. However most of the trackers on websites aren’t Google products, and so they add some serious bloat to your site. As Server-Side Tagging reduces all of a website’s trackers down to a single stream (or a few), it significantly reduces page size.
2. Experience shorter page load times.
Smaller pages equal shorter load times. This is better for SEO and, theoretically, provides lower CPCs in the paid world. What publisher would say no to that?
3. Feed different information to Facebook based on a subscriber’s previous actions.
Until now, the only way to do this was client-side or by relying on a connection between your CRM and Facebook.
4. Own the transformation of your data.
Because the browser is no longer connecting with the third-party vendor, you can ensure everything is stripped out before it’s sent. So you can provide the bare necessities of what the actual call needs and stop Google from getting anything else.
5. Minimise personal information leaks.
Email addresses, phone numbers and credit card numbers are all examples of personally identifiable information (PII) that can currently be accessed by GTM. With server-side tagging, you can control and filter the information that Google receives to ensure that none of this additional user information gets sent.
6. Understand how many people are using ad blockers and private browsing.
An increasing number of people use things like Firefox Private, Brave, and Chrome Incognito to get around paywalls. These are designed to auto-block trackers and so make it hard to gather audience insight. With server-side Tagging, the analytics hits originate from your domain, so traditional ad blockers and private browsers that block trackers won’t work. Note: there are some ethical considerations here but if you’re tracking overall usage this is a really good way to do it without having to rely on your CMS server logs.
7. Enjoy easier user tracking across all devices.
Tracking users across multiple browsers has always been challenging. server-side tagging enables publishers to perform bigger computations than are possible with Client Side Tagging. For example, when information that contains a unique identifier, e.g. a name, comes into a server it now integrates with a CRM. This CRM can then tell you if that same person visited your site on another device. It can then provide insights into their browsing behaviour. This improved ‘stitching together’ of information facilitates a more holistic and meaningful picture of how audiences are interacting with our website.
There’s no denying that the changes to Google Tag Manager can enable the media industry to work smarter. It will certainly be interesting to watch publishers harness these new data opportunities to their full potential.

