
Liquid content was never going to be a publisher product
In Short:
- Liquid content is the publishing industry’s phrase of 2026, but no one has shipped it at scale.
- The reason isn’t execution. It’s that brand-level personalisation has been the wrong target for thirty years.
- The real opportunity sits in CMS architecture and an open standard for structured story data that agents can consume.
If you sit in certain corners of the publishing industry, liquid content has been one of the phrases of 2026. Industry conferences. Trends pieces. LinkedIn posts. Plenty of talk about how this will be the thing that finally reshapes digital publishing.
If you don’t, the short version is this: liquid content describes the idea of stories being reshaped in real time to match each reader’s context, preferences, and behaviour. Different format, different length, different emphasis, all drawn from the same underlying story.
Earlier this year, Dmitry Shishkin, an independent media advisor and former CEO of Ringier Media International, posted a question on LinkedIn that neatly summarised what a lot of us in the industry had been quietly wondering. Everyone’s calling liquid content the next big thing in publishing, he observed. So who has actually shipped it at scale?
His post made an important distinction that matters for the whole conversation. Switching formats, say text to audio or chart to carousel, is the easy part. Shishkin described that work as “not especially hard.” Real liquid content is something different. It’s content that adapts to the individual reader, their preferences, their context, the way they engage. That’s a genuinely hard problem, and publishers haven’t cracked it.
The comments below his post were lively. Plenty of debate about terminology. Suggestions that “adaptive content” might be the better label. Others arguing it was really just personalisation in a new frock.
Lots of opinions. Very few examples.
That silence is the point of this piece.
What everyone agrees on
The term got its mainstream moment in January when the Reuters Institute included it in its annual trends and predictions report. The definition landed cleanly enough. Content that adapts in real time to the user’s context, location, or interaction, built from flexible, reusable blocks rather than fixed articles.
Marcel Semmler, CPO at Bauer Media, framed it well in a recent Digiday explainer. He talked about shifting from content as a finished object to content as structured knowledge that can flow into different formats.
The most visible live attempt so far is the Washington Post’s Your Personal Podcast, which launched in December. Users pick their topics, their AI hosts, their preferred length. Two AI-generated hosts stitch together a briefing based on your reading history.
The industry is nodding along. A name for the concept. A high-profile example. Everyone seems to agree this is where things are heading.
But everyone’s wrong about who’s going to liquify the content.
A confession before the argument
I’ve been one of the people talking about personalisation of content for a decade. So have plenty of people smarter than me. It’s a conversation the publishing industry has been having, in one form or another, for thirty years.

Nicholas Negroponte called it The Daily Me in his 1995 book Being Digital. The idea was a newspaper of one, tailored to the individual. It was a powerful vision, and most of the subsequent thirty years of publishing strategy can be read as an attempt to deliver on it.
Publishers built recommendation engines. They invested in machine learning teams. They ran personalisation pilots in Danish newsrooms and Swedish newsrooms and British newsrooms.
Thomas Baekdal, who has been writing about this for years, put it plainly earlier this year. Personalisation is publishing’s holy grail. Every generation of publishers has chased it. Nobody has ever quite caught it. He even built his own AI-powered news reader to match relevance to each individual. It didn’t work either.
By 2017, when the New York Times signalled its own personalisation plans, the most common reaction from readers was “opt me out.” Digiday ran a piece with the headline “News is not Netflix,” and that headline has aged remarkably well.
So when I say liquid content isn’t going to work at the brand level, I’m not writing from the outside. I’m someone who has helped make the case for brand-level personalisation, watched it fail to deliver, and is now asking whether the premise was wrong from the start.
The Washington Post experiment is already telling us something
Back to the Post’s personalised podcast. It launched in early December 2025. Within 48 hours, the paper’s own head of standards was circulating an internal message acknowledging errors that were, in her words, “frustrating for all of us.”
These weren’t small errors. Pronunciation mistakes were the least of it. The AI made up quotes. It got attributions wrong. It added its own commentary as though the paper had written it.
Semafor, which broke the story, reported that internal testing before launch had shown between 68 and 84 percent of AI-generated scripts failing the paper’s accuracy checks. The product shipped anyway.
Here’s what’s important. This isn’t a story about the Washington Post being careless. The Post has good engineers and good journalists. This is a story about a structural problem that any publisher going down this path will run into.
Presumably, the AI was being asked to turn a published article into a conversational podcast. A published article is a finished product. Everything that was cut from the reporting, the context that didn’t make the word count, the caveats and sourcing decisions that didn’t make it to print, none of it is in there. When the AI needs to go deeper than what the article contains, it has to fill the gap somehow. Inventing quotes and misattributing content is what filling the gap looks like in practice.
That’s not an execution bug. That’s what happens when you ask a model to generate content it doesn’t have the raw material for.
What publishers call personalisation isn’t actually personalisation
This is the part of the argument the industry has been avoiding.
What publishers call personalisation at the brand level is really just filtering. Topic selection. Length adjustment. Format choice. Useful features, but calling them personalisation is a stretch.
Real personalisation would require the system to know the reader, not just the content. To know what they already understand, so the briefing doesn’t rehash background they don’t need. To know what they’ve asked about before, so the story can connect to their existing knowledge. To know which adjacent angles they care about, so the explanation expands where relevant and compresses where it doesn’t.
I’ve heard this discussed on podcasts in ways that make it vivid. Imagine a story about conflict in the Middle East. Your ideal agent would treat that story differently depending on whether you already know the history of the region’s wars, or whether the significance of the Strait of Hormuz is fresh information. It would explain less where you need less. And more where you want more.
The brand cannot know any of that. Even with excellent first-party data, the brand only knows what you did on their property. The personal agent knows what you asked ChatGPT last week, what three other sites you read this morning, what your job is, which angles you’ve engaged with before.
That’s the asymmetry that matters. The brand has the content. Only the agent has the user.
Without both, you’re not doing personalisation. You’re doing summarisation with topic filters.
The original vision was always agents
Here’s the twist that reframes the whole conversation.
When Negroponte wrote about The Daily Me in 1995, he wasn’t proposing that publishers build it. Read the original passage. He imagined an interface agent that would read every newswire and newspaper, catch every broadcast, and construct a personalised summary. A newspaper printed in an edition of one.
That’s not a publisher product. That’s an agent.
The industry has spent thirty years trying to solve a problem the original vision never asked publishers to solve. Brands interpreted The Daily Me as a challenge to personalise their own output, invested heavily in the infrastructure to do it, and have very little to show for the effort.
The agent layer that was always implicit in Negroponte’s thinking simply didn’t exist.
It does now. Perplexity’s Comet browser launched in July 2025. OpenAI’s Atlas followed in October. The Browser Company’s Dia is in the same category. These are agentic browsers, and they’re already summarising, reformatting, and reorganising content inside the browser itself. They’re early and imperfect. They’re also where the action is moving.
The right question for publishers is no longer “how do we build liquid content.” It’s “how do we feed the agents that will.”
So what actually needs to be built
There’s an infrastructure gap between the article as it sits in a publisher’s CMS today and the raw material an agent needs to remix it reliably.
llms.txt, the proposed standard from Answer.AI’s Jeremy Howard, is a start but not the answer. It’s essentially a sitemap for agents. Useful for discovery, not for content.
Cloudflare’s Markdown for Agents, launched earlier this year, is closer. It converts pages to markdown at the network layer. Agents get the content without wasting context on HTML. Cloudflare’s own numbers suggest the token savings run around 80 percent. Genuinely useful. But it’s still just the published article in a cleaner wrapper.
The missing layer is underneath. The CMS as a structured story repository, where the article is one output of a richer information model. When an agent requests the content, it gets the article plus the structured story context that sits beneath it. The reporting. The sourcing. The background. The additional angles that didn’t make the final cut. Machine-readable, schema-driven, specifically designed to give the agent what it needs to reformat reliably.
That’s the infrastructure publishers should be building.
It’s also a real opportunity for CMS platforms and publishing tech vendors to lead. Cloudflare shipped Markdown for Agents as an open standard before the industry had coalesced around anything else. Someone needs to do the equivalent for story structure itself. Not the final answer. Just a starting point the industry can argue with, build on, or adopt.
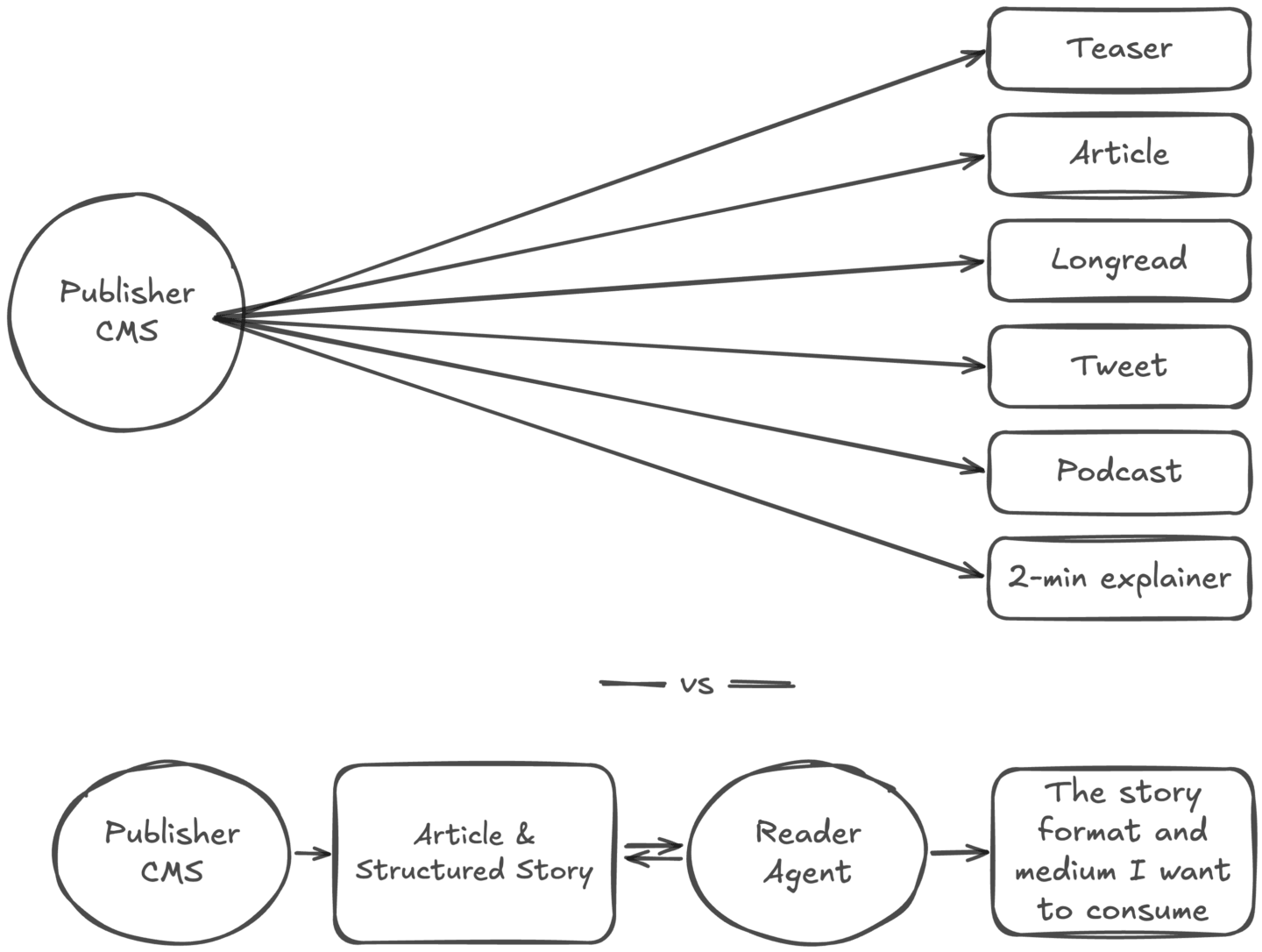
What this means for newsroom workflows and CMS architecture is a bigger conversation.
Where this is heading
This is a prediction, not a proven path. Nobody has built this at full scale yet. There’s every chance the specifics will look different to how I’ve described them.
But the logic keeps pointing in the same direction. Brand-level personalisation has had thirty years to prove itself. The Washington Post case is the latest reminder of what happens when you try to force it. The agent layer is emerging in real time. The infrastructure that connects publishers to those agents is the gap.
Whoever builds that infrastructure first, whether it’s a CMS platform, a publishing tool, or the publishers themselves, will be the ones with something to offer when the agents come asking.
So, who then?
Has anyone actually seen liquid content implemented in a meaningful, repeatable way?
I don’t think anyone has. And I don’t think we’ll see it at any meaningful scale. Not while the industry keeps thinking of this as a publisher product.
The real question is who exposes their story structure early enough to matter. The publishers who get there first, who stop thinking of the article as the finished product and start thinking of it as one expression of a richer underlying story, will be in a very different position to the publishers who spend the next two years trying to ship their own version of a personalised podcast.
Liquid content was never going to be a publisher product. It was always going to be what agents do with publishers’ work.
The sooner the industry accepts that, the sooner the interesting work can start.

