
How URLs affect technical SEO on large publishing sites
Large WordPress sites, the kinds that are synonymous with digital publishers and media brands can have a range of unique technical challenges. These need monitoring and visibility in order for them to remain in good standing with search engines.
An important technical consideration for publishers is the management of URL permutations and malformed URLs being indexed by platforms such as Google. Malformed URLs impact Google’s impression of your website’s general standing, and more importantly, they can waste your crawl budget.
This article will cover:
Table of contents
- What is crawl budget?
- What are WordPress permalinks & URLs?
- What are WordPress URL permutations?
- What is the problem with malformed URL permutations?
- Common issues with URLs in WordPress and how to resolve them
- How to monitor in Search Console
- How long does it take to improve Google Search Console?
- In summary
What is crawl budget?
Crawl budget is the number of pages (URLs) that Google’s web crawler will crawl from a website within a specific time period.
Crawl Budget is the amount of resources that Google allocates to a website for crawling and indexing its pages. The budget is determined by factors such as the site’s size, overall relevance, and the number of external links pointing to the site.
Having a well-optimised site with high-quality content can help to increase a site’s crawl budget, allowing more pages to be crawled and potentially improving the site’s visibility in search results.
What are WordPress permalinks & URLs?
WordPress comes with a number of out-of-the box permalinks / URLs. And while you may not use them, Google is usually pretty smart enough to find them.
Take, for example, a simple WordPress site with 17 pages of content. This might include things like a home page, about page, contact page and a series of blog posts.
While a user can navigate around the site and access these 17 pages quite easily, WordPress will still generate a number of URLs/pages. These URLs may not have any menu links, yet they are still accessible if you know where to look, or are a smart search engine spider, like Google.
Examples of these URLs can be:
- A page for each author on your website (the user that writes the page/post)
- A page for each category / tag used in your blog
- A page for each item in your media gallery (even if it’s not used on the site)
- Any embed objects on a page
- Paginated results for your blog (e.g. Page 2 of 3)
- WordPress’ native search engine results page for any argument passed to it
- WordPress’ various RSS feeds it generates out of the box
- WordPress’ REST API responses
What are WordPress URL permutations?
In a strictly mathematical sense, a permutation is when items in a URL are rearranged or added to.
As a simple example, on a paginated home page, the expected URL permutations could look like this:
mysite.com
mysite.com/page/2/
mysite.com/page/3/
mysite.com/page/100/
This means that WordPress needs to understand how to interpret any variation and either display the content, or show an error to say there isn’t any content.
Managing URL permutations is critically important on large sites that have complex taxonomy structures or leverage custom data structures.
When managing a website with hundreds of thousands of content items, and tens of thousands taxonomy terms, there is no manual way to test every possible combination of URL that could get generated programmatically.
What is the problem with malformed URL permutations?
Content management systems like WordPress are very flexible so they can accommodate all the various requirements a site might have. The problem with this extensive flexibility is that it’s possible to end up with URLs that appear to be valid to a search engine, but are in fact duplicate content or spammy.
In more technical terms, WordPress can accept a wide variety of different URLs, and rather than return a distinct error, returns a successful “200 OK” header. This tells a robot that the page is valid, even though it may then have the robots meta tag declaring not to index the page.
This results in confusion as to whether the search engine should index or noindex that URL.
Common issues with URLs in WordPress and how to resolve them
While every site is unique, there’s usually some common themes or resolutions that can tighten up a search engine spiders’ view of your WordPress site.
1. Ensure empty result pages return hard 404 headers
There are a lot of different ways that spam bots can inject spam into your website. This is usually dependent on the overall tech stack, and how the WordPress theme is developed. A common spam attack will look something like this:
mysite.com/?s=Some+Spam+Link+HTML+here
Many sites will still render a full search template page, with an error saying that there were no results, but then still output the spam. Search engines can get confused and believe that this is in fact a valid URL but may see a robots header to noindex the page, even though it appears to be valid.
2. Excessive URL permutations and manipulations
Another common pattern is Google is appending a query string to a URL and attempting to understand if it is unique content or junk.
mysite.com/author/some-author-name/page/10/?from=sitefrom%3Dsite
The above example is another where WordPress can render out a valid page which would be identical to:
mysite.com/author/some-author-name/page/10/
And while any good template should manage this by using the canonical html tags, it can be ambiguous or deceptive. The manipulated URL above should result in a hard 404 header code and no HTML rendered to the screen as there’s no way a legitimate user could access that page.
3. Common WordPress endpoints
Frustratingly, WordPress ships with a number of endpoints that if not reigned in, can result in needless SEO wastage. Examples of this can include:
mysite.com/post-url/embed
mysite.com/post-url/feed
mysite.com/an-attachment-url/
mysite.com/wp-admin/admin-ajax.php
mysite.com/category/news/feed
As with most digital publishers and media sites powered by WordPress, there are likely to be hundreds of thousands of articles and media attachments. Multiply the above WordPress endpoints that are created for every single article, and you’re talking about an enormous footprint.
Fortunately, major SEO plugins like Yoast are now investing in functionality that allows you to easily turn off all these questionable default features within WordPress.
How to monitor in Search Console
The following report in Google Search Console (GSC) indicates the amount of content that the site has indexed that is either erroneous or duplicative.
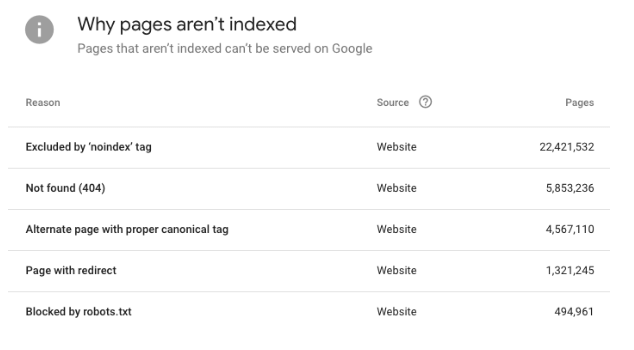
Each reason can be clicked to see the URLs that Google is discovering. This gives you the ability to spot test and understand what’s happening with the CMS. You can also export these as a CSV file to perform deeper analysis in Excel or Google Sheets.
How long does it take to improve Google Search Console?
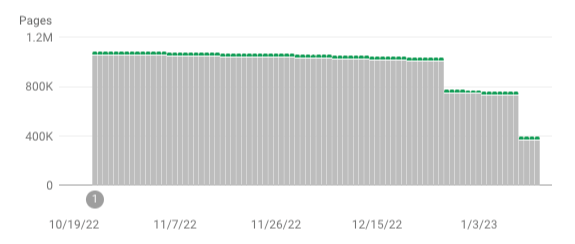
Unfortunately, the turnaround time for Google to recognise when spammy URLs are no longer present can be quite drawn out.
After making adjustments to your site architecture and backend, and setting error codes correctly, it can take months for Google to reflect these changes. However, it will eventually start to detect the pattern of indexed vs non-indexable content, as seen in the chart above.
In summary
URL permutations and malformations should not be ignored as they can have a significant impact on SEO and your crawl budget. Fortunately, there are some efficient ways to stay on top of your URLs and reduce the risk of your tech stack holding back the growth of your business.

